

Алгоритм LSA (Latent Semantic Analysis), также известный как LSI (Latent Semantic Indexing), является одной из техник анализа текстов, применяемой в поисковой оптимизации (SEO). LSA позволяет искать и классифицировать документы, основываясь на их семантическом содержании, а не только на прямом совпадении ключевых слов. Такой подход к анализу текстов позволяет более точно находить похожие документы и улучшать релевантность поисковых результатов.
LSA основан на математической теории линейной алгебры и использует математическое представление текста в виде матрицы термин-документ. В этой матрице каждый ряд представляет собой термин (слово или фразу), а каждый столбец – конкретный документ или текст. Значения внутри матрицы представляют собой веса терминов в каждом документе. Работая с таким представлением, алгоритм LSA может осуществлять поиск семантически связанных документов и группировать их в соответствие с их содержанием.
Основной шаг в алгоритме LSA – снижение размерности матрицы термин-документ путем применения сингулярного разложения (Singular Value Decomposition). Это позволяет нам избавиться от шума и повысить точность сравнения документов. После снижения размерности, LSA использует косинусную меру для определения сходства между документами. Сравнение производится на основе угла между векторами, представляющими документы, чем ближе угол к 0, тем больше сходство.
LSA может быть использован для различных задач в SEO, таких как поиск похожих контента, поиск альтернативных ключевых слов, группирование документов по темам и др. При правильном использовании этот алгоритм может значительно улучшить работу поисковых систем и повысить релевантность поисковых запросов.
Алгоритм LSA для поиска похожих документов
В основе алгоритма LSA лежит идея о том, что слова, которые встречаются в похожих контекстах, имеют схожие смыслы. Алгоритм LSA выделяет скрытые семантические признаки, которые описывают смысловую структуру текстов. Эти признаки могут быть использованы для сравнения и классификации документов.
Для работы алгоритма LSA требуется предварительная подготовка текстовых данных. Сначала тексты проходят через процесс токенизации, в результате которого каждый текст разбивается на отдельные слова или токены. Затем тексты представляются в виде матрицы, где строки представляют собой отдельные документы, а столбцы — отдельные токены.
После этого применяется сингулярное разложение матрицы, которое позволяет выделить наиболее важные семантические компоненты. Затем каждый документ представляется в виде вектора в пространстве этих компонент. Анализ и сравнение этих векторов позволяет оценить степень схожести документов.
Что такое алгоритм LSA?
Алгоритм LSA основан на предположении, что семантическое содержание текста можно представить с помощью латентных семантических аспектов. Латентные семантические аспекты – это скрытые концепции или темы, которые лежат в основе текста и объединяют сходные по смыслу слова и документы. Алгоритм LSA позволяет автоматически выявить эти скрытые аспекты и использовать их для сравнения документов на основе их семантического содержания.
Принцип работы алгоритма LSA
Процесс работы алгоритма LSA состоит из следующих шагов:
- Предобработка текстов. Исходные документы проходят через процесс очистки от стоп-слов, пунктуации и других нежелательных символов. Также применяются методы нормализации, например, лемматизация или стемминг, чтобы свести разные формы слов к единому основанию.
- Построение матрицы термин-документ. Для каждого документа определяется набор терминов, которые в нем встречаются. Затем для всех документов строится матрица термин-документ, где каждый элемент показывает, сколько раз термин встретился в соответствующем документе.
- Сокращение размерности матрицы. Применяется SVD для снижения размерности и выделения главных компонент матрицы. Это позволяет убрать шум и выделить наиболее значимые семантические признаки.
- Определение схожести документов. Для выявления близости между документами используется мера косинусного расстояния между соответствующими строками в новой матрице.
Алгоритм LSA позволяет эффективно решать задачи поиска и классификации документов, а также находить ответы на вопросы, связанные с семантическим содержанием текстов.
Алгоритм LSA в задаче поиска похожих документов
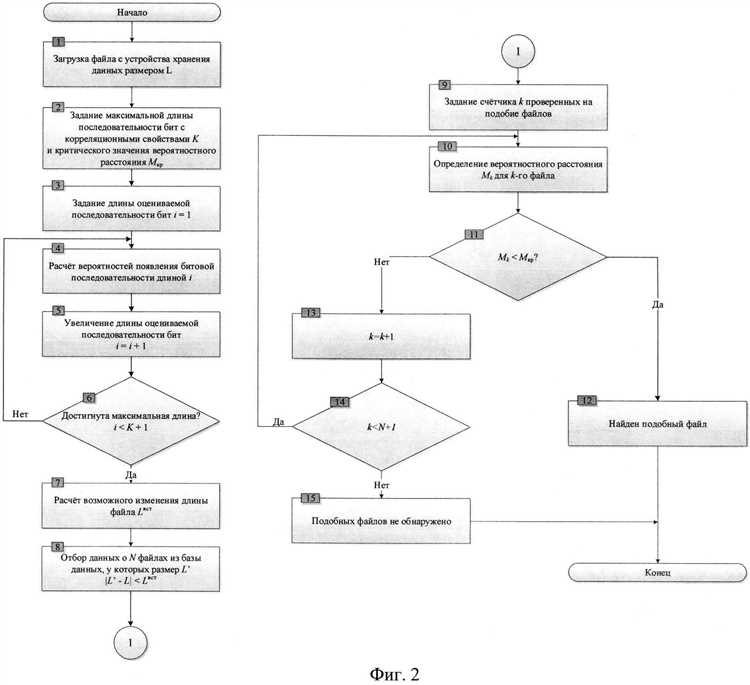
Алгоритм LSA (Latent Semantic Analysis) используется в задаче поиска похожих документов для определения семантической близости между ними. Этот метод основан на математической модели, которая преобразует тексты в числовые векторы, отражающие их семантическую структуру. Затем используется алгоритм снижения размерности для устранения «шума» и избавления от излишней информации.
Для работы алгоритма LSA используется матрица терминов и документов, в которой каждая строка соответствует термину, а каждый столбец — документу. Значение в ячейке матрицы указывает наличие или отсутствие данного термина в конкретном документе. Затем, применяя метод сингулярного разложения (SVD) к этой матрице, получаем три новые матрицы: матрицу терминов-понятий, матрицу документов-понятий и диагональную матрицу сингулярных чисел.
Для поиска похожих документов на основе алгоритма LSA, сравниваются семантические векторы текстов. Это позволяет учитывать не только точное совпадение слов, но и сходство в значении и контексте. Чем ближе семантические векторы двух документов, тем больше вероятность, что они содержат похожую информацию.
Преимущества использования алгоритма LSA
Алгоритм LSA (Latent Semantic Analysis, сокрытое семантическое анализ) представляет собой метод, позволяющий выявить семантические параллели и сходства между документами, основываясь на их содержании. Использование данного алгоритма в поисковой оптимизации (SEO) может принести несколько преимуществ.
- Расширение контекста поиска: LSA позволяет искать не только документы, содержащие точные ключевые слова, но и те, которые могут быть связаны с данным запросом по смыслу. Алгоритм учитывает семантическую близость слов, что позволяет находить связанные с запросом документы, даже если в них отсутствуют точные ключевые слова.
- Устранение синонимов: LSA помогает автоматически распознавать синонимы и использовать их в поиске. Это позволяет учесть разнообразные варианты формулировки запросов со словами, имеющими сходное значение. Таким образом, алгоритм способствует точному и всестороннему поиску связанных документов.
- Снижение влияния шума: LSA позволяет уменьшить влияние шума при анализе большого количества текстовых данных. Благодаря использованию математического подхода и учету статистической информации, алгоритм способен выделить семантическую структуру текста, отделяя более значимые фрагменты от незначительных и содержащих ошибки или повторяющуюся информацию.
Применение алгоритма LSA в различных областях
Алгоритм LSA нашел применение во множестве областей, где требуется анализ текстовой информации и поиск похожих документов. Он широко используется в сфере поисковой оптимизации (SEO), информационного поиска, обработки естественного языка и машинного обучения.
В SEO алгоритм LSA играет значительную роль. Он помогает определять релевантность веб-страниц и выявлять семантическую близость между запросами пользователей и документами на сайте. LSA позволяет снизить влияние синонимичности и морфологических вариаций слов, учитывая семантику текста.
Значительные успехи были достигнуты и в области информационного поиска. Алгоритм LSA позволяет уточнить результаты поиска, исключив нерелевантные документы или находя более подходящие по смыслу запросы. Это способствует более точному поиску информации и повышению удовлетворенности пользователей.
Также алгоритм LSA применяется в обработке естественного языка, где он используется для выявления семантических связей между словами и текстами. Благодаря этому алгоритму возможно автоматическое суммирование текстов, классификация документов, анализ тональности и другие задачи, связанные с обработкой текстовой информации.
Наконец, алгоритм LSA играет важную роль в машинном обучении, особенно в задачах анализа данных. Он может применяться для кластеризации документов, рекомендации контента, обнаружения аномалий и других аналитических задач. Благодаря своей способности находить скрытые семантические связи, LSA стал важным инструментом для работы с текстовыми данными в различных областях применения.